A platform engineer asks two questions on the same morning. First: “I’m renaming this Go method — who calls it?” Second: “I’m bumping our shared Terraform networking module to v3.3.0 — which application repos will run terraform plan against the new version?” The first is a symbol-graph question and Sourcegraph answers it at the top of the category. The second looks similar from a distance, has the same surface verb — “who depends on this” — and is, mechanically, a completely different graph. This post is about why.
A note on what this post is, and isn’t
This is not a competitive teardown. Sourcegraph indexed 54 billion lines of code, created SCIP as an open language-agnostic protocol for code intelligence, and shipped cross-repository navigation at enterprise scale — at the time of writing they host SCIP indexes for over 45,000 public repos and serve customers including Reddit, Stripe, Canva, MongoDB, and Dropbox through their MCP server. Those are real engineering achievements and the product solves real problems well.
The argument here is narrower: code-symbol graphs and infrastructure-artifact graphs are orthogonal categories, and the second one is structurally outside what Sourcegraph’s index produces. This isn’t a flaw in Sourcegraph. It follows from the design choices that make symbol graphs work in the first place.
If you’re a platform engineer evaluating “context infrastructure” — code search, IDPs, cross-repo tooling for humans and agents — the practical takeaway is that most teams need both kinds of graph, and the tools should look as different as the questions do.
Two questions that look similar from a distance
Sit down with a platform team and they will keep coming back to two questions. They sound similar enough that vendor categories blur them.
Question one: I’m changing this function. Who calls it?
This is a code-symbol question. The nodes are functions, methods, classes, types, modules. The edges are references — call sites, imports, type usages, inheritance. The engine that builds this graph is a language indexer: it parses TypeScript or Go or Java with a compiler-aware tool and emits a structured record of where each symbol is defined and where it’s referenced. Sourcegraph is built directly on this category and is the standard against which everything in it is measured.
Question two: I’m bumping this shared Terraform module to v3.3.0. Which application repos will re-plan? Which of them are pinned to v3.2.0, which to ~> 3.2, and which to >= 3.0? Of those that float, which umbrella modules pull mine transitively?
This is an infrastructure-artifact question. The nodes are Terraform modules, Docker base images, Helm charts, Kustomize bases, reusable GitHub Actions workflows, Kubernetes manifests. The edges are artifact references inside infrastructure-as-code source files: source = "git::https://...?ref=v3.2.0", FROM company/base:${BASE_TAG}, dependencies[].repository: oci://..., uses: company/actions/deploy@v2, bases: - ../base-app.
The two graphs have the same surface verb — “who depends on this” — and almost nothing else in common.
What SCIP indexes — and what it doesn’t
The clearest way to see why is to look at what SCIP, the protocol underneath Sourcegraph’s cross-repo navigation, is actually designed to capture.
Sourcegraph’s own description of what SCIP indexes covers two categories of structured data: symbols — carrying definition location, symbol metadata (function vs. class vs. variable vs. etc.), and package ownership including which repository and version defines the symbol — and external symbols — tracking cross-repository dependencies, the symbols defined in other packages, and version data for each dependency.
The keyword is symbols. SCIP indexes the things a compiler or language server understands as named declarations: functions, types, methods, namespaces. To produce this data you need a parser that understands the programming language’s scoping and name-resolution rules. The same Sourcegraph post lists the official language coverage for auto-indexing as TypeScript, JavaScript, Python, Go, Java, Scala, Kotlin, and C/C++. The broader SCIP protocol has additional community indexers — for Ruby, .NET, Dart, PHP, Rust — but the marketed coverage of Sourcegraph’s product is the eight-language list above.
All eight are general-purpose programming languages. The indexer for each is built on the relevant language’s compiler or language server. Notice what isn’t there, and isn’t on the roadmap: HCL, Dockerfile, Helm Chart.yaml, Kubernetes manifest schemas, GitHub Actions workflow YAML, GitLab CI YAML, Kustomize, Ansible playbooks. Not because Sourcegraph forgot about infrastructure-as-code, but because IaC dependency relationships are not symbols. They’re values inside strings that the IaC tool evaluates at deploy or build time. The grammar SCIP describes — definition location, symbol metadata, references — doesn’t fit the shape of those relationships.
This is by design, not by oversight. A language indexer that tried to also produce IaC artifact edges would be solving a different problem with the wrong abstraction.
How Sourcegraph itself recommends answering IaC dependency questions
The strongest evidence for the category split is in Sourcegraph’s own canonical content. Three of their flagship posts on impact analysis and blast radius — the questions that overlap most with the artifact-graph use case — fall back to regex search over manifest files at exactly the point where the answer turns infrastructural.
Multi-repo search: How to search across multiple repositories (March 2025) introduces blast radius and impact analysis as a multi-repo search use case, with the symbol-graph navigation as the precise tool: “It uses SCIP indexes to resolve actual symbol references, so you see real function calls and imports, not just string matches that happen to contain the function name.” For the symbol case, that’s the right answer.
Why code search at scale is essential when you grow beyond one repository (December 2025) walks through “impact analysis before changes” with a worked example. The example reaches for the artifact case — a Go service depending on a shared library — and the recommended query is:
repo:myorg/.* file:go.mod content:"auth-lib"That’s content: regex over the contents of go.mod files, scoped to repos matching myorg/.*. It works. It will find every go.mod in the org that mentions auth-lib. It will not tell you which version each consumer is pinned to in a way the next tool in your pipeline can act on without further parsing, it won’t follow replace directives, and it won’t resolve module path aliases.
Cross-Repository Code Navigation (January 2026) reaches the same pattern for npm. The post’s worked example for “Finding All Usages of a Dependency” is:
context:global file:package.json "your-internal-lib":\s*"[~^]?1\.2\.3" patterntype:regexpAgain — regex over package.json strings. Again it works for finding the files. It doesn’t return a structured consumer list with resolved version constraints across ~, ^, >=, and exact-pin forms; the regex enumerates each one explicitly.
This is not a critique of those posts. They’re honest and they reach for the right tool. Symbol search isn’t the tool for this question — for this question, text matching over manifest files is. But that itself is the observation worth sitting with: when Sourcegraph’s own writers reach for dependency-impact use cases, they pivot from SCIP navigation to regex over manifest files. The reason is structural. SCIP doesn’t index manifest files because manifest files are not source code in the sense SCIP was designed for. They’re declarations a build tool will later resolve against an external system — a module registry, a container registry, a git remote, a chart repository, a Kubernetes API server.
The regex falls back because the symbol graph has no opinion about manifest declarations. It can’t. That’s not what it indexes.
The homepage demo, read carefully
Sourcegraph’s current homepage runs a side-by-side comparison that illustrates the category split better than any external critique could.
The scenario: a developer asks an AI coding agent to add a Role field to a User struct in models/user.go. The baseline agent edits models/user.go and database/user_store.go, declares itself done, and offers a parting suggestion to add a migration. The post-it-note list of “what the agent missed” reads:
- Auth middleware — no role check, any user can access admin routes
- API response DTO — role never returned to clients
- Audit logging — role changes not tracked, no compliance trail
/adminfrontend routes — no guard, UI still accessible to all- Invite flow — new users created without a default role
- 4 integration tests — assert on user shape, will break
Then the same agent runs with Sourcegraph MCP. The agent calls sg_keyword_search "User struct" across 2,847 repositories, gets 31 files across 7 layers, and produces a complete change.
This is a strong demo and the win is real. But notice the exact shape of the problem and the exact shape of the offered tool. Every item on the “missed” list is a cross-cutting code-level concern: a middleware function that checks the user, a DTO type that serializes the user, an audit hook that writes when a user changes, a route guard that consults the user, an invite handler that constructs a user, integration tests that assert on the user shape. Every one of those is a symbol relationship. They are exactly what SCIP indexes and exactly what find_references and keyword_search are designed to surface.
Now imagine an adjacent scenario: a platform engineer is bumping the shared terraform-modules/networking module from v3.2.0 to v3.3.0 because the new version renames a variable. What does an equivalent demo look like?
The missed items aren’t middleware/auth.go, api/dto/user_response.go, routes/admin/guard.ts. They’re: the eight application repos that pin ?ref=v3.2.0 directly in a Terragrunt root, the four repos that pin ~> 3.2 and will float to the new version on next plan, the two umbrella modules in infra-platform-modules that re-export networking and are themselves consumed by another twelve repos, the one repo where the module is pulled through an intermediate terraform-aws-modules/internal-wrapper chain, and the three GitOps repos that reference the module path in an Atlantis repos.yaml. None of those relationships is a symbol. None of them appears in a SCIP index. A search for terraform-modules/networking returns a list of files containing that string and leaves the resolution work — git URL canonicalization, ref-pin parsing, semver constraint evaluation, transitive umbrella resolution, GitOps wiring — to whoever reads the results.
The homepage demo is correct that an AI agent without cross-repository context misses cross-cutting changes. It’s also correct that a symbol graph closes that gap for code-level concerns. It just doesn’t close the same gap for IaC-level concerns, because those concerns aren’t built out of symbols.
What a symbol graph cannot resolve — four worked examples
Concretely, here are four shapes of dependency that show up in every infrastructure-heavy org, and that no code-symbol indexer can resolve without becoming a different product.
1. Terraform module sources with git URLs and ref pins
module "vpc" {
source = "git::https://gitlab.company.com/infra/terraform-modules.git//networking?ref=v3.2.0"
}Nothing here is a symbol. source is an HCL attribute. The value is a single string with overloaded semantics:
git::is a Terraform protocol prefixhttps://gitlab.company.com/infra/terraform-modules.gitis a canonical git URL — which Riftmap normalizes against the same git remote whether it appears ashttps://,git@gitlab..., or with.gitstripped//networkingis a subdirectory inside the module repo?ref=v3.2.0is a git ref pin (could equally be a branch, a tag, or a commit SHA)
To answer “which repos consume the networking module of terraform-modules at v3.2.0” you need a parser that understands this string format and a resolver that walks the repo URL back to a canonical identity. A code indexer sees an HCL attribute assignment with a string literal.
2. Docker FROM with build-arg substitution
ARG BASE_TAG=latest
FROM company/base-runtime:${BASE_TAG}The actual base image consumed in production depends on the --build-arg passed at build time, which usually lives in a separate file — .github/workflows/build.yml, a docker-bake.hcl, a docker-compose.yml, a Makefile target. Resolving the real consumer relationship requires reading the Dockerfile, finding the default, then reading the build invocation to see if it’s overridden. A symbol graph doesn’t model build-time evaluation of CI variables across YAML files.
3. Helm chart consumers across three reference formats
# Chart.yaml dependency
dependencies:
- name: platform-services
version: "~3.2.0"
repository: "oci://registry.company.com/charts"
alias: monitoring # the chart is installed under this name# ArgoCD Application
spec:
source:
chart: platform-services
repoURL: https://charts.company.com
targetRevision: 3.2.1# Flux HelmRelease
spec:
chart:
spec:
chart: platform-services
version: ">=3.0.0 <4.0.0"
sourceRef:
kind: HelmRepository
name: company-chartsAll three reference the same chart. The first uses OCI; the second uses HTTPS; the third uses a Flux HelmRepository pointer that needs to be resolved separately to a registry. The first uses a semver constraint ~3.2.0 and an alias that breaks name-matching in values overrides. The second is an exact pin. The third is an explicit semver range. A complete answer to “who consumes platform-services” requires (a) normalizing all three forms to a canonical chart identity, (b) evaluating each version constraint against the chart’s published versions, (c) following Flux source pointers, and (d) following umbrella charts that re-export platform-services as a subchart. None of this is a symbol relationship. We covered the full Helm case in detail in How to Find Every Consumer of Your Helm Chart.
4. Reusable GitHub Actions workflows
jobs:
deploy:
uses: company/actions/.github/workflows/deploy.yml@v2The uses: value is a single string encoding <owner>/<repo>/<path>@<ref>. Resolving “who uses my deploy workflow” means parsing this format, normalizing the repo identifier, evaluating the ref pin, and following transitive includes when a reusable workflow itself calls other reusable workflows. None of it lives in a programming language’s symbol table.
The pattern across all four: the consumer relationship is encoded in a string inside an IaC declaration, and resolving it requires understanding the IaC tool’s grammar and its evaluation semantics. SCIP indexes none of this, on purpose. A different protocol indexes it, and a different parser estate emits it.
What each tool actually returns
Concretely: imagine you’re the owner of platform-services Helm chart at v3.2.0 and you’re about to publish v3.3.0, which renames a top-level value key.
With Sourcegraph, the recommended pattern is regex over Chart.yaml (and ArgoCD Application manifests, and Flux HelmRelease CRDs, and any shell scripts that call helm install, each a separate query):
context:global file:Chart.yaml "platform-services" patterntype:regexpWhat you get back is a list of file matches: each result is a file path, a line number, a snippet showing platform-services in context, and PageRank-style ranking. You then open each file to read the version constraint, work out which chart identity is being referenced (HTTPS vs OCI vs alias), and manually evaluate which consumers will float to v3.3.0 versus stay on v3.2.x. The work scales with the number of results.
With Riftmap, the call against the same artifact looks like this:
GET /api/v1/artifacts/{helm_chart_id}/consumers{
"artifact": {
"id": "b3790d64-c693-47d5-83b0-3a2c3872faf9",
"artifact_type": "helm_chart",
"name": "helm-library-chart",
"source_repository": {
"full_path": "polaris-works/platform/helm-library-chart"
},
"version": "1.2.0",
"consumer_count": 5,
"is_orphan": false
},
"consumers": [
{
"repository": { "name": "data-helm", "full_path": "polaris-works/data/data-helm" },
"version_constraint": "1.1.0",
"source_file": "Chart.yaml", "source_line": 8,
"is_latest": false,
"import_count": 1
},
{
"repository": { "name": "portal-helm", "full_path": "polaris-works/portal/portal-helm" },
"version_constraint": ">=1.0.0 <2.0.0",
"source_file": "Chart.yaml", "source_line": 8,
"is_latest": true,
"import_count": 1
},
{
"repository": { "name": "logistics-helm", "full_path": "polaris-works/logistics/logistics-helm" },
"version_constraint": "1.2.0",
"source_file": "Chart.yaml", "source_line": 8,
"is_latest": true,
"import_count": 1
},
{
"repository": { "name": "payments-multi-artifact", "full_path": "polaris-works/payments/payments-multi-artifact" },
"version_constraint": "1.2.0",
"source_file": "Chart.yaml", "source_line": 8,
"is_latest": true,
"import_count": 1
},
{
"repository": { "name": "payments-helm", "full_path": "polaris-works/payments/payments-helm" },
"version_constraint": "~1.2.0",
"source_file": "Chart.yaml", "source_line": 8,
"is_latest": true,
"import_count": 1
}
],
"total_consumers": 5,
"consumers_on_latest": 4,
"consumers_lagging": 1,
"latest_version": "1.2.0"
}Five consumers, four pin shapes the resolver normalises (exact-current 1.2.0, exact-behind 1.1.0, tilde range ~1.2.0, explicit range >=1.0.0 <2.0.0), and consumers_lagging: 1 already evaluated against the chart’s published version — the consumer table is the structured answer to “who consumes my chart at v1.2.0” without leaving anything for the agent to parse.
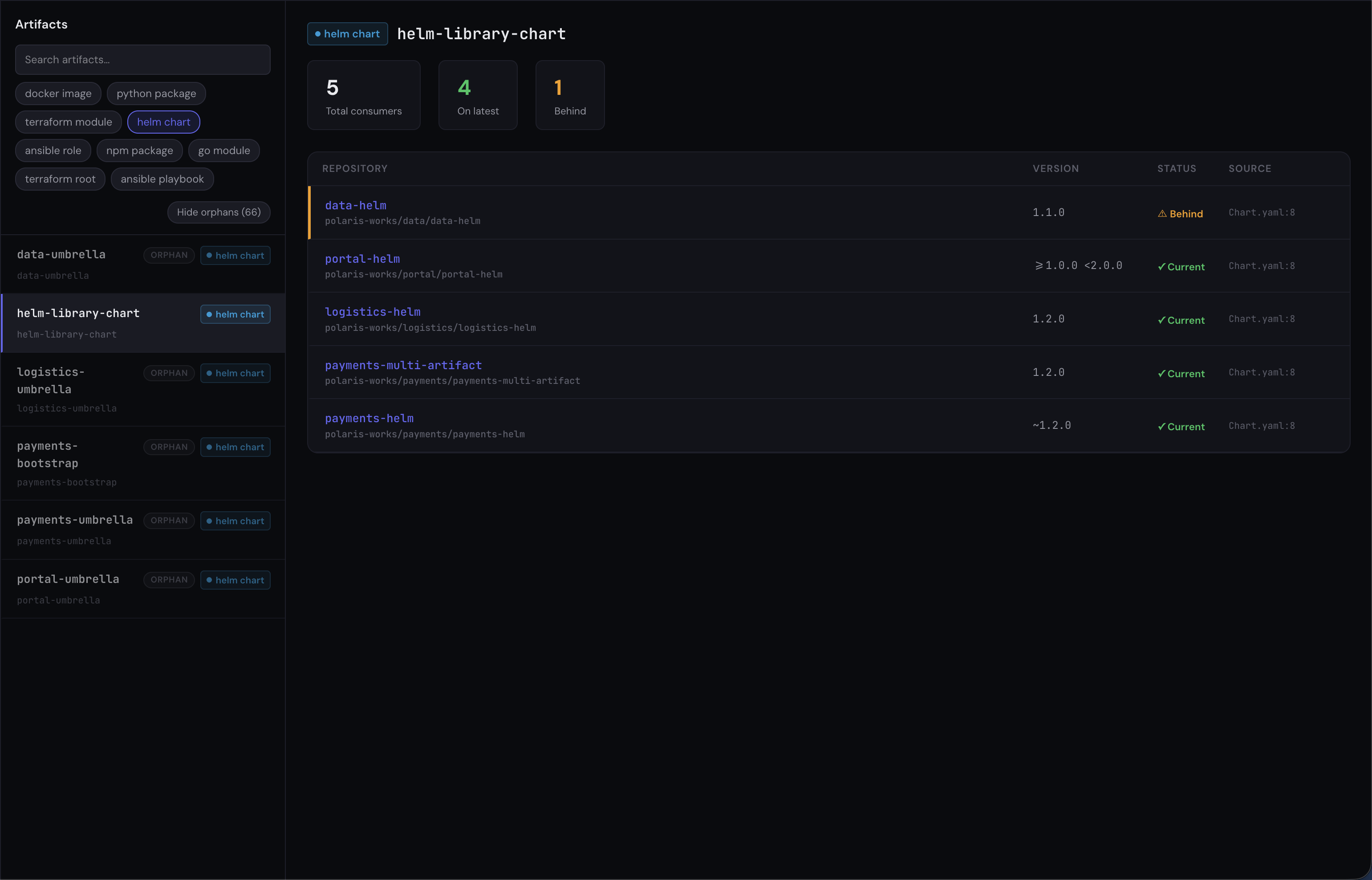
What you get back is a structured consumer list. The same chart identity has been resolved across HTTPS, OCI, and Flux pointer forms before you see it. Each consumer carries its version constraint (~3.2.0, >=3.0.0 <4.0.0, exact 3.2.1) already evaluated against the published versions, so consumers within range of v3.3.0 are flagged. Umbrella charts that re-export platform-services are followed transitively; their downstream consumers appear with their own constraints. The work doesn’t scale with the result count — the structure has been resolved once, server-side, by the parser estate.
Neither answer makes the other one wrong. They’re answers to different questions, with different shapes, returned by different machinery.
Steelmanning the obvious objections
A few obvious objections, taken at their strongest.
”Couldn’t Sourcegraph add IaC parsers?”
Yes, in principle. SCIP is an open protocol. Someone could write scip-hcl or scip-helm and emit Terraform-shaped or Helm-shaped records into the same index format Sourcegraph already serves.
The hard part isn’t the parser. The hard part is the evaluator. The output of scip-hcl would have to be a different kind of fact — not “this symbol is defined here and referenced there” but “this source = "git::..." string, when evaluated by Terraform’s module installer against the current state of remote git repositories, resolves to repo X at commit Y, in the context of which an attribute called Z is defined, which is consumed by a module block in repo W that depends on commit V of the same module.” That’s not a symbol-graph fact. It’s an artifact-graph fact. You can serialize it in SCIP if you want, but the data model and the consumer code paths in Sourcegraph (go-to-definition, find-references, version-aware symbol lookup) are built for the symbol case. You’d have to build a parallel pipeline that resolves git URLs, parses semver constraints across ~/^/>=, follows umbrella charts, evaluates ARG defaults, walks reusable workflow chains, and normalizes container image references across registries. At that point you’ve built a different product that happens to share an index format with the first one.
The same logic applies to any code-symbol vendor — Cody, Greptile, OpenGrep, Augment, the rest of the category. The category isn’t structurally suited to the artifact question. That’s the whole point.
”Can’t an LLM with Cody’s @-mention just figure this out?”
This is the version of the objection that requires the most care, because Anthropic’s lead on Claude Code has staked out a clear public position on the opposite side. In Boris Cherny’s Pragmatic Engineer interview, the team described trying local vector databases, recursive model-based indexing, and other RAG-shaped approaches for agentic search. The conclusion was that “plain glob and grep, driven by the model, beat everything,” and Claude Code shipped with that as the architecture.
Don’t read this as a counter-argument to refute. Read it as structural validation of the category split. The Cherny bet is specifically that for symbol-level questions inside a working session, an LLM driving primitive tools (glob, grep, read) outperforms a pre-built index whose maintenance cost includes staleness, permissions, and integration complexity. That’s a coherent and defensible position for the symbol case, and a careful reader of the Pragmatic Engineer interview will notice why it works: when the model greps for a function name, the relevant truth — the call site, the import statement, the type signature — is sitting in the source code the model can read. The model can iterate. It runs another grep, opens another file, and converges on a verified answer within the session. The primitive tool plus the model plus the source code is a complete loop.
The artifact case breaks the loop because the truth isn’t sitting in the source files in a form grep can converge on.
Grep terraform-modules/networking across an org and you get a list of files that mention the string. What grep cannot return — and what reading those files cannot recover without rebuilding the parser estate inside the conversation — is the resolved answer: which of those references canonicalize to the same module across git::https://, git@gitlab:, and stripped-.git URL forms; which version constraints (~3.2.0, ^3.0.0, >=3.0.0 <4, exact 3.2.1) include v3.3.0 after evaluation against the published version list; which Flux HelmRepository source pointer in gitops/sources/ resolves to which registry; which umbrella module re-exports networking and pulls in its own downstream consumers; which ARG-substituted FROM line in a Dockerfile actually resolves to which base image after CI evaluation. The resolver complexity doesn’t surface in grep output. It has to be built once, somewhere, against the IaC tools’ grammars and against external registries — or the model has to rebuild it on every query, against text matches, with no audit trail.
That’s why dependency questions want deterministic answers and why “92% confidence that these are your consumers” is unshippable. You can’t merge a change to a shared Terraform module against an LLM probability distribution over its consumer set; you need the actual set, derived from actual source, with an audit trail you can hand to the consumer teams before you ship. The deterministic-graph approach has to survive even if Cherny’s bet wins everywhere it’s making its bet — because in the artifact case the model can’t iterate to verification from primitive tools. The verification primitive is the parser estate itself.
”Doesn’t terraform graph already solve this?”
terraform graph is excellent and frequently misunderstood. It produces the DAG of a single configuration — the resource dependencies inside one root module, used by Terraform’s planner to schedule create/update/destroy operations in the correct order. It is not cross-repo, it is not cross-ecosystem, and it has no opinion about Docker base images, Helm charts, or reusable workflows. The same applies to Atlantis stack graphs, Spacelift stack dependencies, and HashiCorp Cloud Platform’s Module Explorer — each solves a slice of the Terraform-orchestration problem from within a specific runner. The artifact graph in this post sits one level up: source-derived, cross-repo, cross-ecosystem, runner-agnostic.
What this means for the agent layer
If you’ve followed agent-context infrastructure in 2026 at all, you’ve watched every vendor in adjacent categories reposition around “the intelligence layer for AI coding agents and developers.” Sourcegraph 7.0 (February 25, 2026) used that exact phrase to formalize the shift. Their MCP server lists Reddit, Stripe, MongoDB, Canva, Dropbox as customers using keyword_search, nls_search, go_to_definition, find_references, commit_search, diff_search, deepsearch, and a small set of related primitives.
That’s the right shape of MCP server for symbol-level agent context. It’s the shape Sourcegraph has been building toward for over a decade and the customer list reflects that fit.
It’s also not the only MCP server a serious agent setup will compose by 2027.
The architecture taking shape across the agent ecosystem is multi-context composition. An agent working on a non-trivial cross-cutting change pulls from several specialized context layers: symbol context (the code-graph layer Sourcegraph dominates), artifact context (the IaC dependency layer Riftmap exists to provide), ticket and project context (Linear, Jira, GitHub Issues), documentation and decision context (Notion, Confluence, ADR repos), observability and runtime context (Datadog, Honeycomb, Sentry, log aggregators). Each layer has its own grammar, its own retrieval primitives, its own freshness model, its own MCP server. The agent’s orchestration layer composes them.
In that picture, Riftmap and Sourcegraph aren’t alternatives and they aren’t complements in the usual “we play well together” sense either. They’re peers in a converging architecture. The fact that the IaC artifact layer now has dedicated infrastructure is not evidence that Sourcegraph is wrong about code-symbol context. It’s evidence that the architecture is maturing — that the field has gotten serious enough about agent context to specialize the layers instead of asking one tool to serve every question.
Both MCP servers can sit in the same agent’s tool list. They answer questions Sourcegraph was built to answer well, and questions Sourcegraph was reasonably not built to answer at all. The composition is the point.
The short version
Symbol graphs index how code calls itself. The nodes are functions and types; the edges are references; the indexer is a language-aware parser; the protocol is SCIP. Sourcegraph is the standard-bearer for this category and has been for over a decade. For “where is this function called, who depends on this API, what’s the blast radius of a refactor” — symbol graph, Sourcegraph, end of discussion.
Artifact graphs index how infrastructure consumes itself. The nodes are Terraform modules and Docker images and Helm charts and reusable workflows; the edges are artifact references inside IaC source; the parser estate is one-per-ecosystem and the resolution heuristics are IaC-tool-specific. For “who consumes my Helm chart at v3.2.0, which repos will re-plan on a Terraform module bump, what’s the blast radius of changing a shared GitHub Actions workflow” — artifact graph, Riftmap, built for exactly this.
The questions sound similar. The graphs are different shapes. Most platform teams have both questions, and the right answer is to use both kinds of tool — the same way a serious agent setup in 2026 composes multiple specialized context layers instead of asking any one tool to serve every question.
That’s the test for when this category has matured: when nobody is surprised that the IaC dependency graph lives behind its own MCP server.
I have since measured this across two real organisations — Prometheus and Cloud Posse — counting every cross-repo edge: the infrastructure share runs from a third to nearly all, and not one edge is a code symbol. The breakdown is in I counted every cross-repo edge in two real orgs.
The category has also since gained its largest entrant. GitLab shipped Orbit in June 2026, a property graph of code symbols and SDLC objects spanning a whole GitLab.com group, served to agents over MCP. It is a serious graph, and it draws the same line this post draws: no HCL parser, no Dockerfile parser, no artifact edges. I spent two days in the docs and the data model and wrote up what GitLab Orbit maps, and the layer it cannot reach.
There is a second axis worth separating from this one. This post splits graphs by what they index — code symbols versus infrastructure artifacts. A different split asks how the graph is produced: parsed from the manifests your repositories already declare, or modeled by hand in a catalog someone maintains. I drew that line against Port’s Blueprints in modeled graphs and parsed graphs, and pushed declared vs inferred further into a three-way split — declared, inferred, or registered — in a separate post on how a tool comes to know an edge exists at all.
This is the kind of question Riftmap is built to answer. It scans your GitHub or GitLab organisation with a read-only token, parses Terraform, Docker, Helm, Kustomize, Kubernetes, GitHub Actions, GitLab CI, Ansible, Go modules, and npm, and builds the cross-repo artifact graph as a queryable surface — for engineers in the UI, for agents over MCP. Five minutes to first graph. If you’ve read this far, the free tier is here.
If you’re interested in the underlying parsing work for any single ecosystem, the Find Every Consumer series goes one ecosystem at a time: Docker base images, Terraform modules, GitHub Actions workflows, Helm charts, Go modules.